Nested L2→GW→L1 messages tree design for Gateway
Introduction
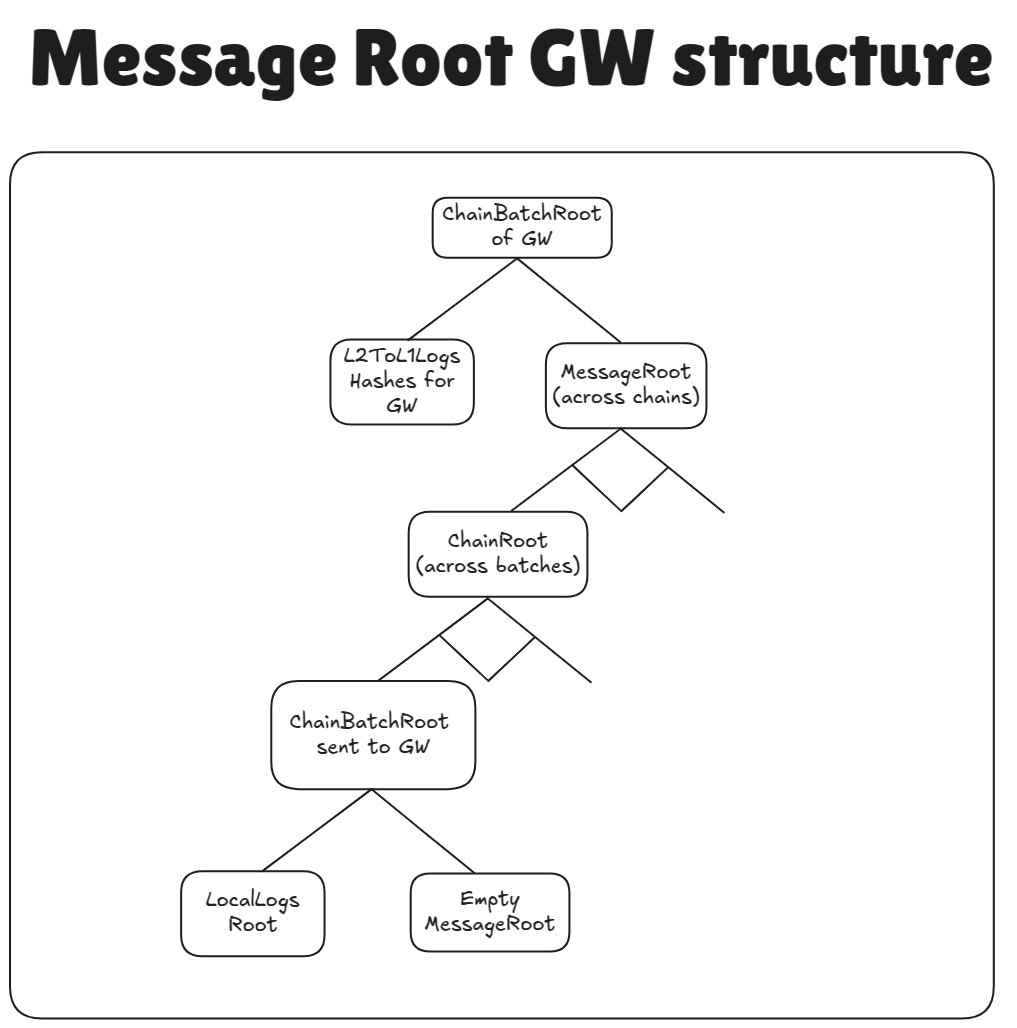
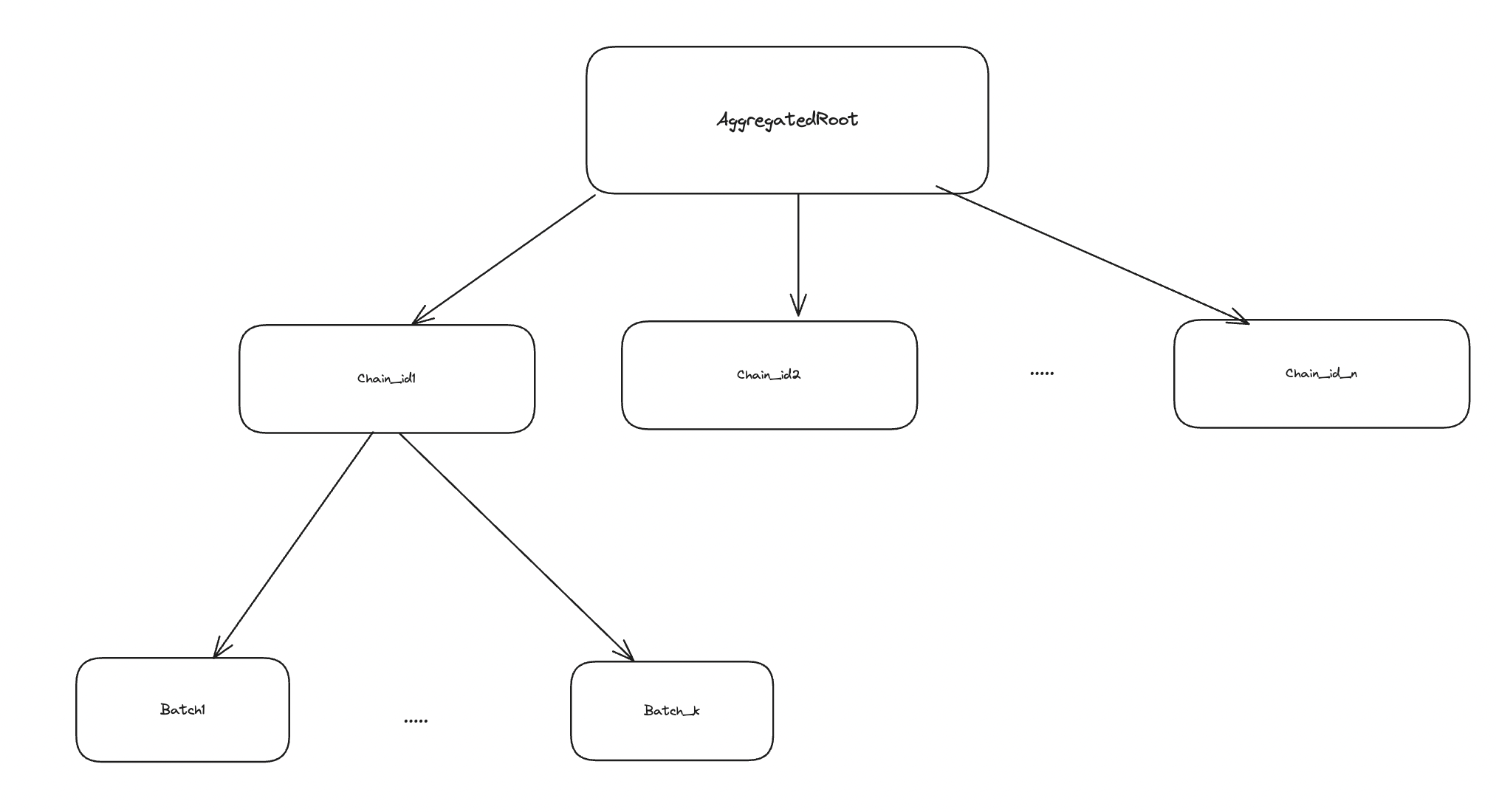
This document assumes that the reader is already aware of what SyncLayer (or how it is now called Gateway) is. To reduce the interactions with L1, on SyncLayer we will gather all the batch roots from all the chains into the tree with following structure:
Note:
“Multiple arrows” from AggregatedRoot to chainIdRoot and from each chainIdRoot to batchRoot are for illustrational purposes only.
In fact, the tree above will be a binary merkle tree, where the AggregatedRoot will be the root of the tree of chainIdRoot, while chainIdRoot is the merkle root of a binary merkle tree of batchRoot.
For each chain that settles on L1, the root will have the following format:
settledMessageRoot = keccak256(LocalRoot, AggregatedRoot)
where localRoot is the root of the tree of messages that come from the chain itself, while the AggregatedRoot is the root of aggregated messages from all of the chains that settle on top of the chain.
In reality, AggregatedRoot will have a meaningful value only on SyncLayer and L1. On other chains it will be a root of an empty tree.
The structure has the following recursive format:
settledMessageRoot = keccak256(LocalRoot, AggregatedRoot)LocalRoot— the root of the binary merkle tree overUserLog[]. (the same as the one we have now). It only contains messages from the current batch.AggregatedRoot— the root of the binary merkle tree overChainIdLeaf[].ChainIdLeaf = keccak256(CHAIN_ID_LEAF_PADDING, chain_id, ChainIdRoot)CHAIN_ID_LEAF_PADDING— it is a constant padding, needed to ensure that the preimage of the ChainIdLeaf is larger than 64 bytes and so it can not be an internal node.chain_id— the chain id of the chain the batches of which are aggregated.ChainIdRoot= the root of the binary merkle treeBatchRootLeaf[].BatchRootLeaf = keccak256(BATCH_LEAF_HASH_PADDING, batch_number, SettledRootOfBatch).
In other words, we get the recursive structure, where for leaves of it, i.e. chains that do not aggregate any other chains, have empty AggregatedRoot.
Appending new batch root leaves
At the execution stage of every batch, the ZK Chain would call the MessageRoot.addChainBatchRoot function, while providing the SettledRootOfBatch for the chain. Then, the BatchRootLeaf will be calculated and appended to the incremental merkle tree with which the ChainIdRoot & ChainIdLeaf is calculated, which will be updated in the merkle tree of ChainIdLeafs.
At the end of the batch, the L1Messenger system contract would query the MessageRoot contract for the total aggregated root, i.e. the root of all ChainIdLeafs . Calculate the settled root settledMessageRoot = keccak256(LocalRoot, AggregatedRoot) and propagate it to L1.
Only the final aggregated root will be stored on L1.
Proving that a message belongs to a chain on top of SyncLayer
The process will consist of two steps:
- Construct the needed
SettledRootOfBatchfor the current chain’s batch. - Prove that it belonged to the gateway.
If the depth of recursion is larger than 1, then step (1) could be repeated multiple times.
Right now for proving logs the following interface is exposed on L1 side:
struct L2Log {
uint8 l2ShardId;
bool isService;
uint16 txNumberInBatch;
address sender;
bytes32 key;
bytes32 value;
}
function proveL2LogInclusion(
uint256 _chainId,
uint256 _batchNumber,
uint256 _index,
L2Log calldata _log,
bytes32[] calldata _proof
) external view override returns (bool) {
address hyperchain = getHyperchain(_chainId);
return IZkSyncHyperchain(hyperchain).proveL2LogInclusion(_batchNumber, _index, _log, _proof);
}
Let’s define a new function:
function proveL2LeafInclusion(
uint256 _chainId,
uint256 _batchNumber,
uint256 _mask,
bytes32 _leaf,
bytes32[] calldata _proof
) external view override returns (bool) {}
This function will prove that a certain 32-byte leaf belongs to the tree. Note, that the fact that the leaf is 32-bytes long means that the function could work successfully for internal leaves also. To prevent this it will be the callers responsibility to ensure that the preimage of the leaf is larger than 32-bytes long and/or use other ways to ensuring that the function will be called securely.
This function will be internally used by the existing _proveL2LogInclusion function to prove that a certain log existed
We want to avoid breaking changes to SDKs, so we will modify the zks_getL2ToL1LogProof to return the data in the following format (the results of it are directly passed into the proveL2LeafInclusion method, so returned value must be supported by the contract):
First bytes32 corresponds to the metadata of the proof. The zero-th byte should tell the version of the metadata and must be equal to the SUPPORTED_PROOF_METADATA_VERSION (a constant of 0x01).
Then, it should contain the number of 32-byte words that are needed to restore the current BatchRootLeaf , i.e. logLeafProofLen (it is called this way as it proves that a leaf belongs to the SettledRootOfBatch). The second byte contains the batchLeafProofLen . It is the length of the merkle path to prove that the BatchRootLeaf belonged to the ChainIdRoot .
Then, the following happens:
- We consume the
logLeafProofLenitems to produce theSettledRootOfBatch. The last word is typically the aggregated root for the chain.
If the settlement layer of the chain is the chain itself, we can just end here by verifying that the provided batch message root is correct.
If the chain is not a settlement layer of itself, we then need to calculate:
BatchRootLeaf = keccak256(BATCH_LEAF_HASH_PADDING, SettledRootOfBatch, batch_number).- Consume one element from the
_proofsarray to get the mask for the merkle path of the batch leaf in the chain id tree. - Consume
batchLeafProofLenelements to construct theChainIdRoot - After that, we calculate the
chainIdLeaf = keccak256(CHAIN_ID_LEAF_PADDING, chainIdRoot, chainId
Now, we have the supposed chainIdRoot for the chain inside its settlement layer. The only thing left to prove is that this root belonged to some batch of the settlement layer.
Then, the following happens:
- One element from
_proofarray is consumed and expected to maintain the batchNumber of the settlement layer when this chainid root was present as well as mask for the reconstruction of the merkle tree. - The other element from the
_proofcontains the address of the settlement layer, where the address will be checked.
Now, we can call the function to verify that the batch belonged to the settlement layer:
IMailbox(settlementLayerAddress).proveL2LeafInclusion(
settlementLayerBatchNumber,
settlementLayerBatchRootMask,
chainIdLeaf,
// Basically pass the rest of the `_proof` array
extractSliceUntilEnd(_proof, ptr)
);
The other slice of the _proof array is expected to have the same structure as before:
- Metadata
- Merkle path to construct the
SettledRootOfBatch - In case there are any more aggregation layers, additional info to prove that the batch belonged to it.
Trust assumptions
Note, that the _proof field is provided by potentially malicious users. The only part that really checks anything with L1 state is the final step of the aggregated proof verification, i.e. that the settled root of batch of the final top layer was present on L1.
It puts a lot of trust in the settlement layers as it can steal funds from chains and “verify” incorrect L2→GW→L1 logs if it wants to. It is the job of the chain itself to ensure that it trusts the aggregation layer. It is also the job of the STM to ensure that the settlement layers that are used by its chains are secure.
Also, note that that address of the settlement layer is provided by the user. Assuming that the settlement layer is trusted, this scheme works fine, since the chainIdLeaf belongs to it only if the chain really ever settled there. I.e. so the protection from maliciously chosen settlement layers is the fact that the settlement layers are trusted to never include batches that they did not have.
Additional notes on security
Redundance of data
Currently, we never clear the MessageRoot in other words, the aggregated root contains more and more batches’ settlement roots, leading to the following two facts:
- The aggregated proofs’ length starts to logarithmically depend on the number of total batches ever finalized on top of this settlement layer (it also depends logarithmically on the number of chains in the settlement layer). I.e. it is
O(log(total_chains) + log(total_batches) + log(total_logs_in_the_batch))in case of a single aggregation layer. - The same data may be referenced from multiple final aggregated roots.
It is the responsibility of the chain to ensure that each message has a unique id and can not be replayed. Currently a tuple of chain_batch_number, chain_message_id is used. While there are multiple message roots from which such a tuple could be proven from, it is still okay as it will be nullified only once.
Another notable example of the redundancy of data, is that we also have total MessageRoot on L1, which contains the aggregated root of all chains, while for chains that settle on L1, we still store the settledBatchRoot for the efficiency.
Data availability guarantees
We want to maintain the security invariant that users can always withdraw their funds from rollup chains. In other words, all L2→GW→L1 logs that come from rollups should be eventually propagated to L1, and also regardless of how other chains behave an honest chain should always provide the ability for their users to withdraw.
Firstly, unless the chain settles on L1, this requires a trusted settlement layer. That is, not trusted operator of the gateway, but it works properly, i.e. appends messages correctly, publishes the data that it promises to publish, etc. This is already the case for the Gateway as it is a ZK rollup fork of Era, and while the operator may censor transactions, it can not lie and is always forced to publish all state diffs.
Secondly, we guarantee that all the stored ChainIdLeafs are published on L1, even for Validiums. Publishing a single 32 byte value per relatively big Gateway batch has little price for Validiums, but it ensures that the settlement root of the gateway can always be constructed. And, assuming that the preimage for the chain root could be constructed, this gives an ability to ability to recover the proof for any L2→GW→L1 coming from a rollup.
But how can one reconstruct the total chain tree for a particular rollup chain? A rollup would relay all of its pubdata to L1, meaning that by observing L1, the observer would know all the L2→GW→L1 logs that happened in a particular batch. It means that for each batch it can restore the LocalRoot (in case the AggregatedRoot is non-zero, it could be read from e.g. the storage which is available via the standard state diffs). This allows to calculate the BatchRootLeaf for the chain. The only thing missing is understanding which batches were finalized on gateway in order to construct the merkle path to the ChainRootLeaf.
To understand which SL was used by a batch for finalization, one could simply brute force over all settlement layers ever used to find out where the settledBatchRoot is stored.. This number is expected to be rather small.
Legacy support
In order to ease the server migration, we support legacy format of L2→L1 logs proving, i.e. just provide a proof that assumes that stored settledMessageRoot is identical to local root, i.e. the hash of logs in the batch.
To differentiate between legacy format and the one, the following approach is used;
- Except for the first 3 bytes the first word in the new format contains 0s, which is unlikely in the old format, where leaves are hashed.
- I.e. if the last 29 bytes are zeroes, then it is assumed to be the new format and vice versa.
In the next release the old format will be removed.